Hadoop - Computation to Data
An open source, Java-based programming framework which supports processing and storage of large data sets in Reliable, Scalable, distributed computing environment, where its library itself is designed to detect and handle failures at the application layer.

Hadoop Distributed File System (HDFS): distributed file system that provide high-throughput access to application data

Hadoop YARN: framework for job scheduling and cluster resource management.
Hadoop MapReduce: YARN-based system for parallel processing of large data sets

 Ambari: web-based tool for provisioning, managing, and monitoring Hadoop clusters which includes support for Hadoop HDFS, Hadoop MapReduce, Hive, HCatalog, HBase, ZooKeeper, Oozie, Pig and Sqoop. It provides dashboard for viewing cluster health heatmaps and ability to view MapReduce, Pig and Hive applications visually alongwith features to diagnose their performance characteristics in a user-friendly way
Ambari: web-based tool for provisioning, managing, and monitoring Hadoop clusters which includes support for Hadoop HDFS, Hadoop MapReduce, Hive, HCatalog, HBase, ZooKeeper, Oozie, Pig and Sqoop. It provides dashboard for viewing cluster health heatmaps and ability to view MapReduce, Pig and Hive applications visually alongwith features to diagnose their performance characteristics in a user-friendly way

Avro: a remote procedure call and data serialization framework. It uses JSON for defining data types and protocols, and serializes data in a compact binary format
Cassandra: scalable multi-master database designed to handle large amounts of data across many commodity servers, providing high availability with no single point of failure. It is a type of NoSQL database.
Chukwa: open source data collection system for monitoring large distributed system, built on top of HDFS and MapReduce framework and inherits Hadoop’s scalability and robustness
Apache Flume. A tool used to collect, aggregate and move huge amounts of streaming data into HDFS.
Apache HBase. An open source, non-relational, distributed database; that supports structured data storage for large tables.
Apache Hive. A data warehouse that provides data summarization, query and analysis;
Impala an open source massively parallel processing query engine. It is an interactive SQL like query engine that runs on top of HDFS
Apache Mahout is a Scalable machine learning and data mining library to produce free implementations of distributed or otherwise scalable machine learning algorithms focused primarily in the areas of collaborative filtering, clustering and classification
Apache Oozie. A server-based workflow scheduling system to manage Hadoop jobs
Apache Phoenix. An open source, massively parallel processing, relational database engine supporting OLTP for Hadoop that is based on Apache HBase
Apache Pig. A high-level platform for creating programs that run on Hadoop. It can execute its Hadoop jobs in MapReduce, Apache Tez, or Apache Spark
Apache Sqoop. tool designed to transfer data between Hadoop and relational database servers
Spark. A fast engine for big data processing capable of streaming and supporting SQL, machine learning and graph processing. It is a cluster-computing framework, which means that it competes more with MapReduce than with the entire Hadoop ecosystem. For example, Spark doesn't have its own distributed filesystem, but can use HDFS. Spark uses memory and can use disk for processing, whereas MapReduce is strictly disk-based
Apache Storm. An open source data processing, or distributed real-time computation system. It makes it easy to reliably process unbounded streams of data, doing for realtime processing what Hadoop did for batch processing
Apache ZooKeeper. An open source configuration, synchronization and naming registry service for large distributed systems. it is a centralized service for maintaining configuration information, naming, providing distributed synchronization, and providing group services. All of these kinds of services are used in some form or another by distributed applications
Cloudera is a software company that provides Apache Hadoop-based software, support and services, and training to business customers, a sponsor of the Apache Software Foundation
Hortonworks is a leading innovator in the data industry, creating, distributing and supporting enterprise-ready open data platforms and modern data applications. Our mission is to manage the world’s data
NiFi supports powerful and scalable directed graphs of data routing, transformation, and system mediation logic
Apache Giraph is an iterative graph processing system built for high scalability, it is currently used at Facebook to analyze the social graph formed by users and their connections
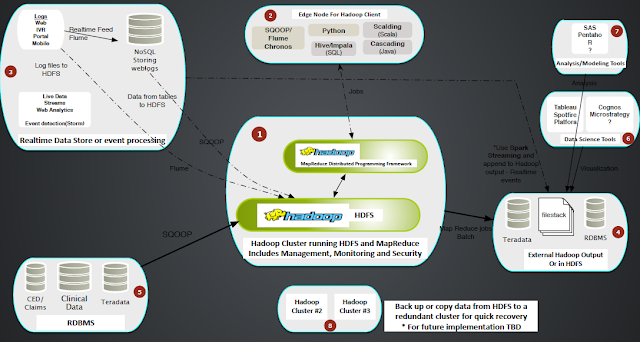
Existing Infrastructure Architecture

HadoopHadoop Common: utilities that support other Hadoop modules
Hadoop Distributed File System (HDFS): distributed file system that provide high-throughput access to application data

Hadoop YARN: framework for job scheduling and cluster resource management.
Hadoop MapReduce: YARN-based system for parallel processing of large data sets



Avro: a remote procedure call and data serialization framework. It uses JSON for defining data types and protocols, and serializes data in a compact binary format
Cassandra: scalable multi-master database designed to handle large amounts of data across many commodity servers, providing high availability with no single point of failure. It is a type of NoSQL database.
Apache Flume. A tool used to collect, aggregate and move huge amounts of streaming data into HDFS.
Apache HBase. An open source, non-relational, distributed database; that supports structured data storage for large tables.
Apache Hive. A data warehouse that provides data summarization, query and analysis;
Impala an open source massively parallel processing query engine. It is an interactive SQL like query engine that runs on top of HDFS
Apache Mahout is a Scalable machine learning and data mining library to produce free implementations of distributed or otherwise scalable machine learning algorithms focused primarily in the areas of collaborative filtering, clustering and classification
Apache Oozie. A server-based workflow scheduling system to manage Hadoop jobs
Apache Phoenix. An open source, massively parallel processing, relational database engine supporting OLTP for Hadoop that is based on Apache HBase
Apache Pig. A high-level platform for creating programs that run on Hadoop. It can execute its Hadoop jobs in MapReduce, Apache Tez, or Apache Spark
Apache Sqoop. tool designed to transfer data between Hadoop and relational database servers
Spark. A fast engine for big data processing capable of streaming and supporting SQL, machine learning and graph processing. It is a cluster-computing framework, which means that it competes more with MapReduce than with the entire Hadoop ecosystem. For example, Spark doesn't have its own distributed filesystem, but can use HDFS. Spark uses memory and can use disk for processing, whereas MapReduce is strictly disk-based
Apache Storm. An open source data processing, or distributed real-time computation system. It makes it easy to reliably process unbounded streams of data, doing for realtime processing what Hadoop did for batch processing
Apache ZooKeeper. An open source configuration, synchronization and naming registry service for large distributed systems. it is a centralized service for maintaining configuration information, naming, providing distributed synchronization, and providing group services. All of these kinds of services are used in some form or another by distributed applications
Hadoop Architecture

Cloudera is a software company that provides Apache Hadoop-based software, support and services, and training to business customers, a sponsor of the Apache Software Foundation
Hortonworks is a leading innovator in the data industry, creating, distributing and supporting enterprise-ready open data platforms and modern data applications. Our mission is to manage the world’s data
NiFi supports powerful and scalable directed graphs of data routing, transformation, and system mediation logic
Apache Giraph is an iterative graph processing system built for high scalability, it is currently used at Facebook to analyze the social graph formed by users and their connections


Comments
Post a Comment